
When Pagely first launched in 2006, the idea was simple: we wanted to make it easier for people to get online with WordPress. We grew rapidly at first, starting out as a WordPress software-as-a-service solution and quickly evolving into the first managed hosting platform for WordPress.
Over six years, we stumbled, got up, tried again, and developed Pagely. Each new version of our platform was better than the one before and made each month since we started our best month to date.
This is our origin story, from 2006 to 2012. In it, we share with you how our company came to be, and highlight some of the technical aspects of what powered the Managed WordPress Hosting system we developed during this time.
Before Pagely, We Built Websites for Clients
Every idea starts with a problem. Ours was simple: we had too many clients.
Back in the internet dark ages, pre-Twitter, my wife, Sally, and I ran a web consultancy shop in Phoenix, Arizona. We served all manner of clients with your typical fare of web-related services, like website design (remember Dreamweaver?), SEO, light programming, and the like.
Around late 2005, we started using WordPress for deploying client sites. These were the early days of WordPress — launched only two years earlier — but even then we could see that it was going somewhere. WordPress 1.2 showed promise.
Sally wondered why it took so long to create custom sites, one day saying, “I thought you guys just clicked a few buttons and added some images and the website appeared. Why can’t it be that easy?”
Turns out, she was some kind of prophet.
We went upmarket as our business grew, charging tens of thousands of dollars rather than hundreds of dollars. Soon we were turning away repeat business from early clients. After Sally heard me turning away our fourth client one day, telling them we had raised our prices and couldn’t reduce our fees, she said to me, “Josh, you’ve said ‘no’ to a few thousand dollars today. We are leaving money on the table!”
Identifying the Opportunity: A SaaS for Managing WordPress
So there it was, an opportunity staring us in the face. How could we still serve these lower-paying customers profitably? We had to automate — we needed to give them the power to build their website themselves.
Pagely v0.0 was born. Or as it was known then, Flare9.com.
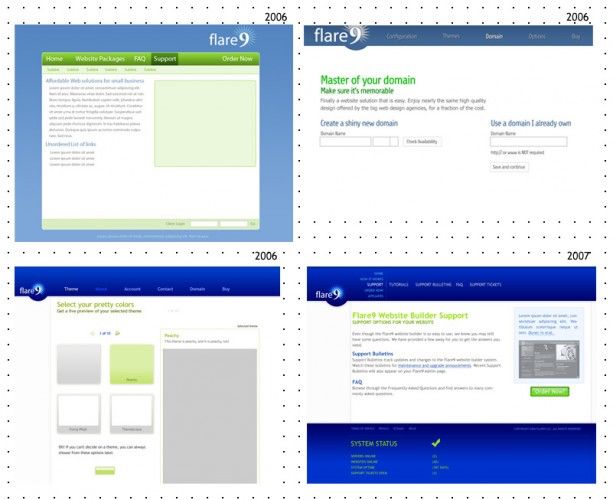
Our market research found no one else in the space. As in: no one else was offering anything like an automated software-as-a-service approach to managing self-hosted WordPress sites.
There were consultants clicking buttons for people, but Flare9 was the first-of-its-kind WordPress SaaS.
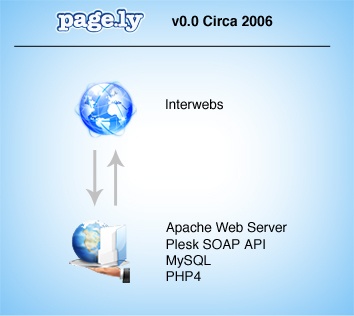
Pagely v0.0: Under the Hood
Our first crack at a Managed WordPress Hosting solution (we’d try again later) was coded by our only employee at the time, Joshua Eichorn. He bootstrapped a slick little system that could intake and bill orders and send them over a socket connection to our “installer” library, which then ran around moving files, creating databases, and restarting Apache.
As an aside: Joshua is one of the most talented programmers I’ve ever worked with. After working at Pagely for a year and then going on to work as Director of Engineering at Stumbleupon, he returned to Pagely, becoming our CTO.
At the time we were using the Plesk hosting panel on all our web servers. We also tapped into the Plesk SOAP API to handle much of the vhost and DB config for us. The server was a simple Dual-Core Xeon hosted at EV1 (now defunct).
Here’s a rundown of our basic setup:
- One server doing everything (PHP4, MySql, Apache, email, etc.)
- Simple code library written in the then brand new Code Igniter framework
- Plesk SOAP API for vhost configs
- Very basic file and database backups
Looking back, we didn’t have:
- Caching plugins
- HTTP acceleration, like Varnish or NGINX
- Firewalls
- Memcache or APC
- Automatic updates for WordPress or plugins
It Worked! Now the Hard Part: Finding Customers
The provisioning system worked well, and in late 2006, over the course of two to three months, we had forty or fifty paying customers.
Hosting, for the most part, was easy. Marketing was where we struggled.
You’ve got to remember, this was pre-social media, during the heyday of Google PPC. No one had really heard of WordPress yet and we had a really hard time getting anyone to notice us outside of our local business community.
After a couple of months trying to get noticed, we turned off active sign-ups and moved on.
Try, Try Again: Rebooting Pagely in 2009
In 2009, with the economy in a skid, we were ready to try again. I was really tired of client work, and we still had 70–80% of our old customers still faithfully paying their monthly fees.
We started rewriting the code base and chose a better name: Pagely.
We re-launched, but again our marketing missed the mark. Pagely was still ahead of its time and users still weren’t quite sure what we were offering.
So in late 2009, after many months of retooling, we went back to the market with an improved Managed WordPress Hosting solution.
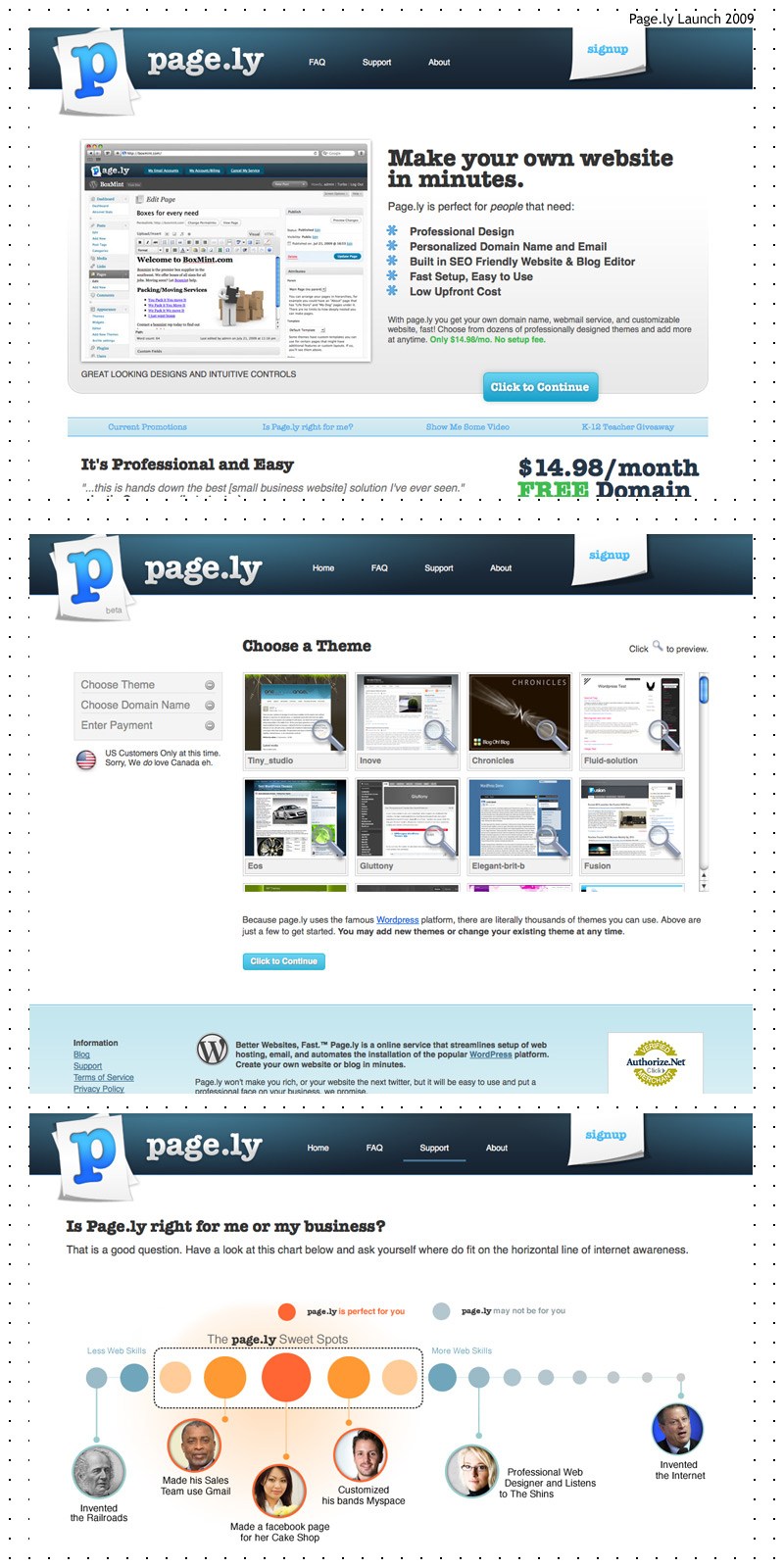
The new platform was based on the core logic of the prototype — providing an automated way to deploy WordPress-powered sites. But this system, Pagely 1, offered groundbreaking improvements:
- Automatic WordPress core updates
- Automatic WordPress plugin updates
- Automatic nightly backups
- An integrated “hosting panel” via a custom-developed WordPress plugin that communicated with our core system and wrapped vital hosting administration tasks like DNS, email, and billing management without the bloat of a full cPanel or Plesk interface
- Our one-of-a-kind white screen eliminator
Initially, we pushed the “choose your theme” aspect of our platform, letting customers select from a library of chosen WordPress themes. But this turned out to be a conversion killer — users stressed over which theme to use and ultimately abandoned the cart. (We later downplayed this feature in Pagely 2, which we’ll get to shortly.)
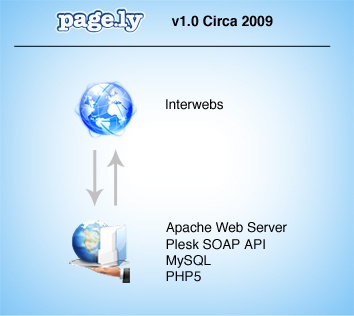
Pagely 1: Under the Hood
Pagely 1 used the same infrastructure as our earlier prototype — a single LAMP box using the Plesk SOAP API, but now using PHP 5. Really, not that exciting.
This Time Around, Pagely Worked
Everything worked like a charm, and by the end of 2009, we had a modest hundred or so users.
Customer feedback was interesting. Some people loved Pagely, while others hated it. There were people who would troll us by saying, “Oh, I can do X myself. Why would I pay for it?” Those who got it, got it and understood what we were trying to do: make WordPress better through automating technical tasks.
By early 2010, as our customer count neared five hundred, we knew we needed to scale. Our hosting provider at the time wasn’t helpful. Nothing against them, but they were a hands-off provider — they basically made sure the server was plugged in, and that’s about it.
So we searched for a new host. We needed a host we could partner with to not only address our security concerns but also assist with fine-tuning and managing the hardware setup.
And that’s when we found Firehost.
Finding a New Home and Beginning to Scale
Firehost (now Armor) met all of our criteria. Plus, I knew the CEO. They were small (at the time) and nimble like us, and security was their core offering.
In one evening, we migrated our single server over to Firehost.
We also went through a couple of site redesigns during this time:
Better Security
The move to Firehost added multiple levels of security to our system. Not only did it boost our offering, but it value-added — we stressed this benefit in our marketing and haven’t strayed from it since.
Our security features at the time included:
- Managed redundant firewall protection
- Managed redundant web application firewalls
- Managed redundant DoS/DDoS mitigation
- Multi-level intrusion prevention and detection
- Real-time virus scanning
- Real-time malware scanning
Pagely 2: Under the Hood
Our new and improved system featured:
- All nodes HA (High Availability)
- Four web servers running Plesk & Litespeed (and DNS)
- A single MySQL node
- The Plesk SOAP API for vhost configs
- Opcode Caching
It was around this time that we also started experimenting with WordPress caching plugins.
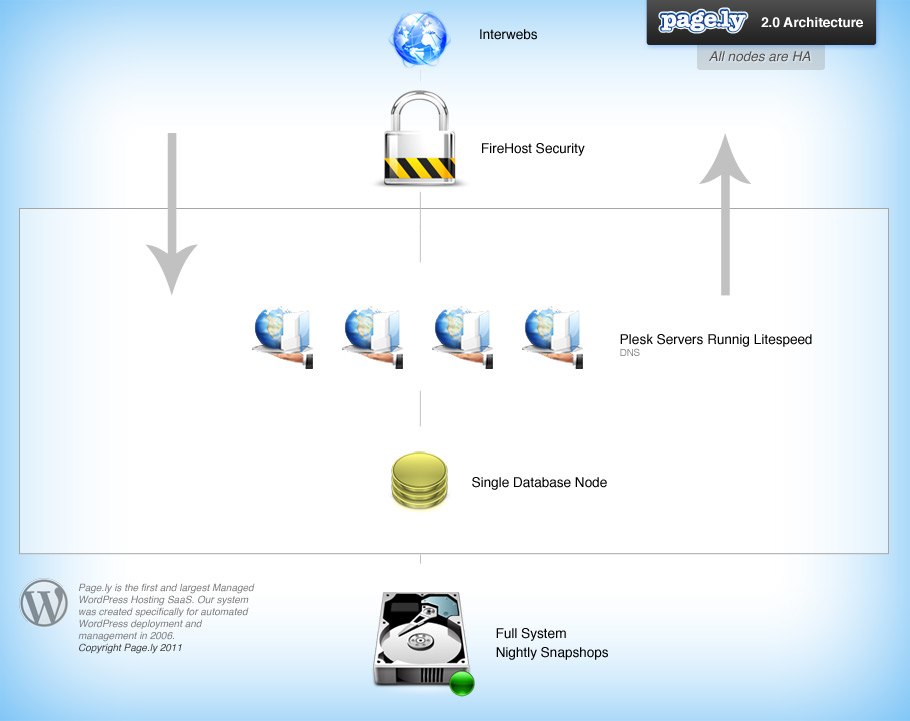
We were moving in the right direction. We had better security and enough power to serve thousands of domains.
Speed-wise, this setup was okay. Initial hit (not full page load) times were about 200–400ms. If you had been a Pagely customer around this time, you would’ve felt some pain: thanks to our single-server-per-user setup, we had to take down an entire node whenever we needed to run maintenance.
In 2010, we flew past one thousand customers. It was also the year we:
- Launched our Reseller program, allowing folks to white-label Pagely;
- Deployed our Vertical Platform, allowing select partners deeper integration with custom reseller packages;
- Switched email to a third party provider;
- Had a PowerUp system for a while, packaging bundles of themes and plugins from our providers. We moved away from even though it is was fairly successful.
New Players Enter the Managed WordPress Hosting Market
By 2010, new players began arriving on the Managed WordPress Hosting scene that we had started. It was inevitable. We had done the hard yards to prove the space had legs and that there was revenue to be made, and no good idea goes un-copied for long. We were also making a name for ourselves in the WordPress community, and that had helped get the word out.
A couple of interesting points regarding these new arrivals:
At SXSW in 2010, I went to a WordPress barbecue held at a co-working space in Austin, where I handed out a few shirts and talked to folks about Pagely. One guy I distinctly remember talking to must’ve really been paying attention because a few months later he co-founded a competing company.
This company’s co-founder solicited us about using our technology to power their new offering rather than re-inventing the wheel. I was receptive to the idea (it fit squarely with our collaboration-over-competition philosophy) and agreed to a phone call, which never took place — they decided to reinvent the wheel after all.
Another new player wasn’t content with merely re-factoring our idea, but was “heavily” inspired by our marketing. I had to pull them up on the overt similarities between our website copy.
At the end of the day, we didn’t — and we still don’t — see any of these companies as competitors. We work from a mindset that with tens of millions of WordPress sites online, there’s more than enough space for other Managed WordPress Hosting providers.
Time to Go BIG: Scaling with Pagely 3
By late 2010, it was time to scale again. The system choices we had made when we started out with Pagely were fitting at the time but, as we grew, and kept growing, our old system was struggling under the strain.
So we embarked on what would be an all-consuming project: Pagely 3.
With Pagely 3, our goal was to design a system that was more reliable, secure, scalable, and — importantly — performant.
Our plan was to develop Pagely 3 next to Pagely 2 — build a mansion next to the condo and then, come moving day, pack everyone up and move next door. Sounds simple, right? As it turned out, the build process was long and not without problems.
We started by consulting some of the best and brightest minds in the web community. I spent hours talking to my good friend Joe Stump (former Lead Architect at Digg), among others who had “scaling” knowledge. We developed a simple plan: use small nodes to do specific tasks and scale out in layers.
We decided we needed dedicated machines for MySQL, web, Varnish, Memcache, etc. We also needed load balancers out front and robust, fast storage behind it.
We also had to dump Plesk. It was fine when Pagely was small, but it simply didn’t scale.
Here’s how we built Pagely 3 in five phases:
Phase 1
Our first task was to add more database servers — two new slaves coming off the master. Then we added WordPress’s HyperDB system-wide to segment those reads and writes. We went from a single 8 Core 17GB machine to 3–4 Core 10GB machines. The slaves happily processed 700–800 queries a second at 0.20 load.
Phase 2
Next, we set up new storage with NFS. At first, we went with a solid 700GB disk, but decided it would be better to serve ten 70GB disks up to the web nodes by NFS4. Firehost also upgraded all our storage to Fibre. The disk speeds were crazy fast. We did all hard file operations directly on the storages nodes, which also sped things up.
Phase 3
We set up Zeus load balancers out front in a failover configuration, with dual Varnish nodes directly behind it. This gave us a lot of flexibility, allowing us to segment and direct traffic around or through specific Varnish nodes directly to some or all of the web nodes. It was also fault-tolerant — if both Varnish nodes fell over, everything would move gracefully to the web nodes. With this setup, we could serve pages and static assets in 20–50ms — a 4x improvement over Pagely 2.
Phase 4
Next, we set up some other nodes to handle a few management tasks like Puppet, Memcache, cron jobs, backups, logging, etc. We also gutted all the code that relied on Plesk since we were no longer going to use it and bashed together a temporary set of scripts to install and manage our system.
Finally, we directed certain types of traffic to specific nodes tuned for the task. We didn’t blanket all web nodes with all traffic. As an example, we set up wp-cron.php commands to hammer a pool of servers all day, allowing others to work without nasty processes sapping CPU.
Going into 2012, we varied between sixteen and twenty-four4 nodes running, depending on load. Here’s what the Pagely 3 server topology looked like:
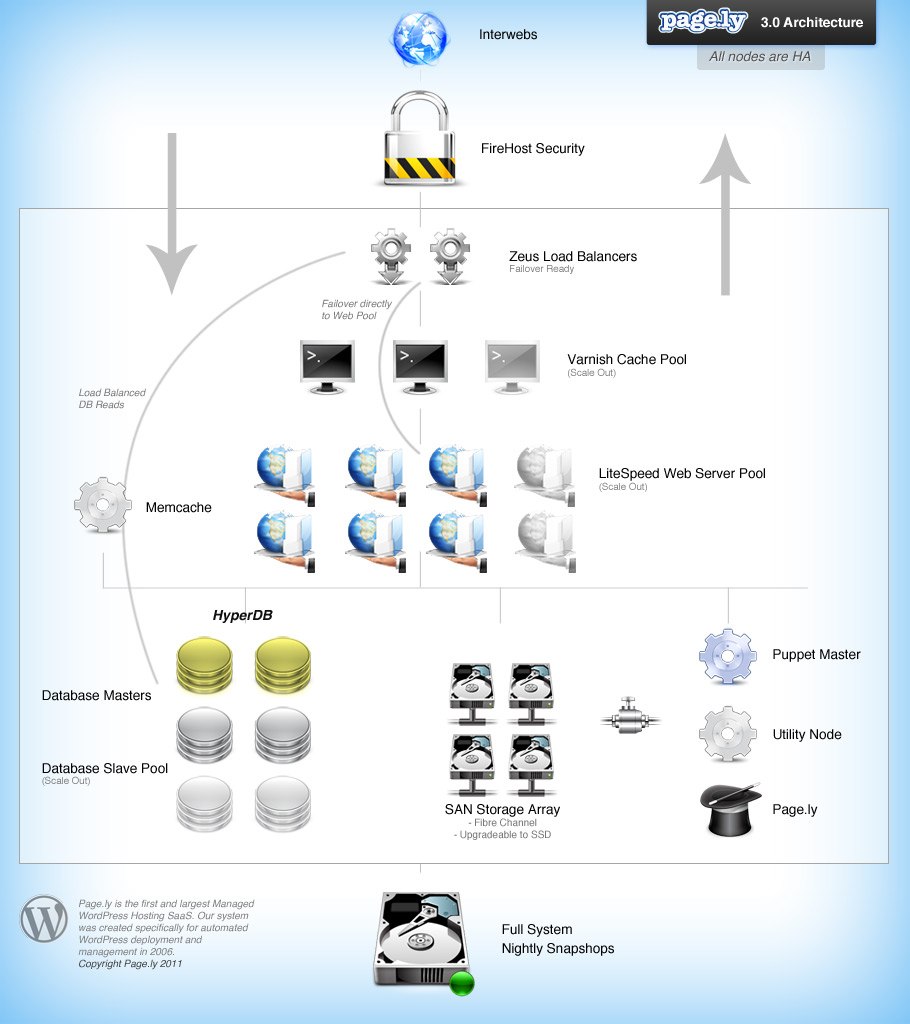
El Pollo Diablo: Top-Tier Hosting
In 2010, we launched El Pollo Diablo, our Managed WordPress Hosting service for top-tier customers.
It was essentially the same architecture stack with a hybrid approach. We routed traffic through the load balancers to a dedicated Varnish node and web server pool specific to the customer. Sometimes the customer would run their own MySQL pool as well; other times they took advantage of our MySQL cluster. This flexibility allowed customers true “dedicated” resources but also offered the use of our redundant and failover safe systems as needed.
Obviously, we don’t want to share every piece of the puzzle, as there were a few blackops systems we put in place to add that little extra awesome that made Pagely special back then.
Phase 5: Transitioning Customers
Moving clients to the new system wasn’t easy. Over the three months from October 2011 to just after Christmas, we moved one of the old Plesk servers at a time, rsynced all that data over, then popped IPs off those nodes and onto the load balancers. We moved our last customer after Christmas and finally shut down the old nodes. After every block, we would tune and test, uncover bad mojo, and cure it.
That period between October and December 2011 was probably the hardest our company has had to face, and hopefully ever will face. We had a hard time getting the balance just right, redoing our storage setup and Varnish configs at least four times while serving live traffic.
It’s hard to plan for what you don’t know. For example, a nasty bug in PHP at the time essentially lstated a file four to eight times every single time it requested it. On local storage, you probably wouldn’t notice the hit, but over NFS with the millions of files we were accessing millions of times a day, it was literally shredding the SAN and sending IO on the web nodes through the roof.
This was just one of the handful of things we found at scale.
Again, we had to work through each of these things under live conditions. And once we moved a block of customers, there was no going back.
There was some customer attrition as we worked through the issues. We’d won them over with a solid offering and stellar support, but even the most understanding customers would only hang around so long if we couldn’t keep the system up for more than ten hours at a time.
We wished them well, knowing they’d be back — they always came back because other Managed WordPress Hosting solutions “just don’t stack up” (one customer’s words, not mine).
After three tough months, investing $100,000 in labor and new hardware while losing customers, we continued to grow. We hired four employees, more than doubled our customer base, and redesigned our website.

Fine-Tuning Pagely 3
Going into 2012, we investigated alternate storage systems and looked at everything from gluster to netapp, and GFS. We were constantly fine-tuning and tweaking the Varnish nodes to maximize hit rate and delving deep into WordPress itself to tune it for our system.
At this point, we had essentially forked WordPress. We maintained a set of patches we applied to new versions of the core software and tested before rolling them out to the customers.
We also looked at alternate caching systems around the database and object cache to make full use of Memcache; APC was also running on a very narrow fileset that could be expanded.
We still had our work cut out for us, but we were making progress daily instead of monthly.
Updating the Pagely Dashboard
Our business dashboard had performed its duties well over the years, but it was time to retire it. I had coded it in CodeIgniter and it allowed us to perform nearly any task needed without ever hitting the command line. We could pull up accounts, orders, domains, and DNS; manage affiliates and resellers, and even track our growth.
Here’s a look at the dashboard we retired:
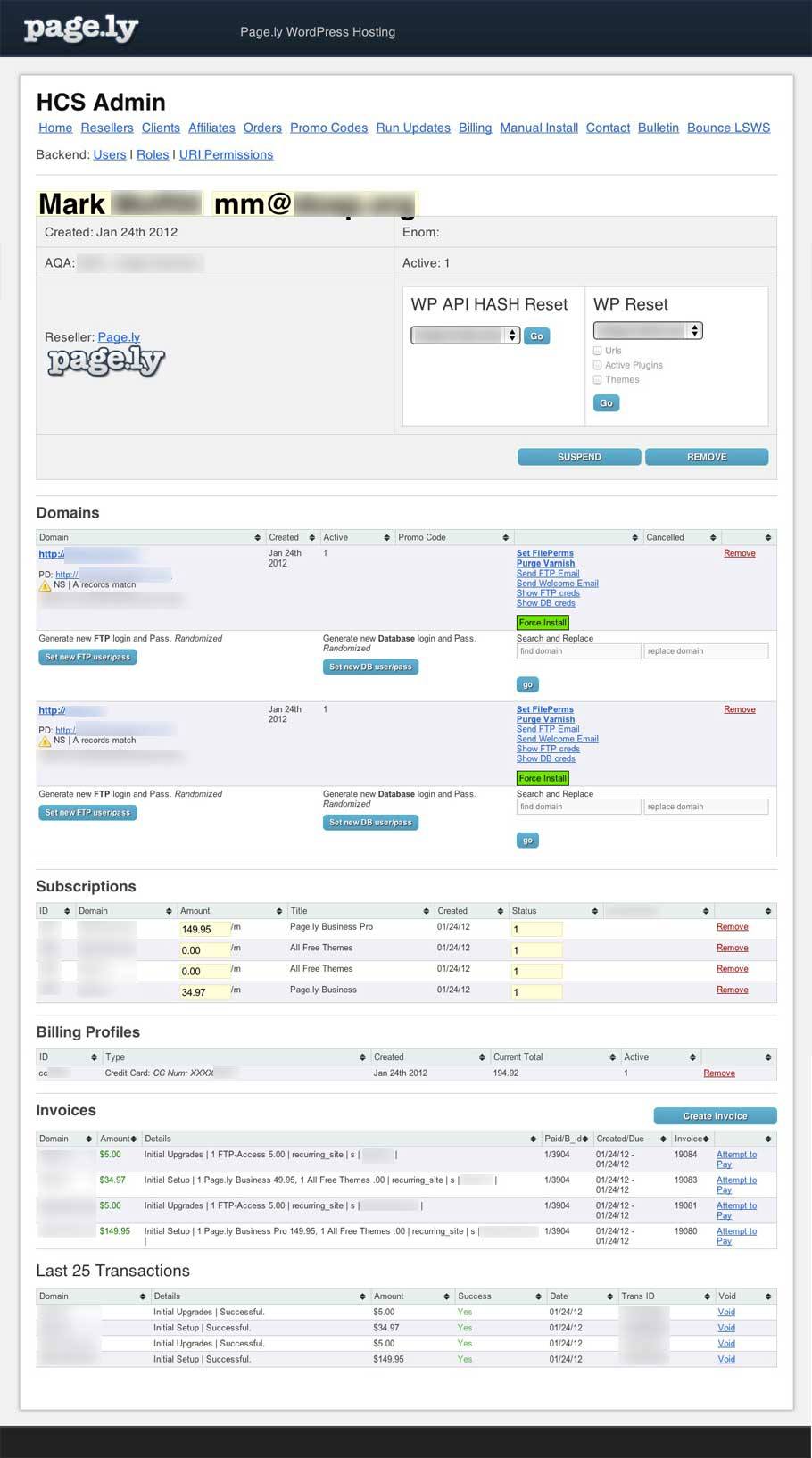
The dashboard setup worked from a system management and app deployment perspective, but it was slow and prone to errors. It worked exceptionally well when managing five hundred domains and adding two or three a day. But it came under strain when managing thousands of domains and adding ten to twenty a day.
A Brand New Backend for Pagely 3
Up through Pagely 2, we were using the Plesk SOAP API to manage vhost deployments on specific web nodes. Then with Pagely 3, we bashed together some scripts to replace Plesk. But those were temporary fixes, and in early 2012 we rewrote our whole deployment and management system upon a CodeIgniter REST API.
Our new account dashboard included:
- Reseller management
- Account management
- Domain management
- Billing system
- DNS management
- Domain registration
- App provisioning system
- Reporting/logging
- Affiliate management
- Infrastructure management
- Product management
- Support integration
As you can see, there’s much more that goes into running a functional and successful Managed WordPress Hosting business than just helping customers install WordPress.
A Brand New Front-End for Pagely 3, Too
We wanted a new UI that was light, responsive, and worked well with our new API service methodology (more on that next). Enter Bootstrap. Our CodeIgniter client apps served up the data, and Bootstrap made that data easy to interact with.
Here’s what our new dashboard looked like:
Our API Service Methodology
We wanted to make everything in Pagely a RESTful service; that was our methodology. So we built an API specifically for the installer and server/system processes, another API for account/user-related functions, and another specifically for job queuing, etc. This approach allowed us to:
- Decouple code
- Maintain narrowly defined unit tests
- Craft lightweight REST client apps and UIs
- Document it and make it accessible to partners
Importantly, it allowed us to expose many of our core provisioning and account-managed API endpoints to authorized partners so they could re-sell Pagely managed WordPress on their site.
Additionally, it allowed more developer-savvy partners to generate reports and lists of their current customers, and manage accounts for those customers. It also let them manage their integration points with Pagely, such as defining which themes, plugins, or content would be preinstalled on their new customer sites.
Pagely: A Proudly Bootstrapped Company
In 2010, a large and well-known hosting company approached us about acquiring Pagely. In 2011, the same thing happened again with another company. We also toyed with the idea of raising funds that year.
At the end of the day, we always came back to the same conclusion: we like what we do, we like doing it our way, and we like doing it on our terms.
We had a vision of the type of company we wanted Pagely to grow up to be, and that vision hasn’t changed. We didn’t want to maximize profits with gimmicks at the expense of customers, just to appease a board or make our earn-out. We didn’t have a “win at all costs” mindset that pushed integrity and professionalism aside.
Our vision was and still is, to be the best at what we do, provide a quality service, and treat our customers and employees how we wish to be treated — with fairness and honesty.
I believe these values are compatible with making a healthy profit, not exclusionary to it. Could we achieve this goal with outside capital? Sure. Are we going to waste time trying to convince a VC to play along? Probably not. Someday, perhaps. I am not anti-VC, but I am anti getting into bed with someone that may not share our values.
In 2012, Pagely’s Future Was Bright — and Still Is
From a failed concept in 2006 to the second go in 2009, after insane growth and success in 2010 and server madness in 2011, the future looked bright in 2012 — and it only got better from there, as we now know.
I hope you enjoyed this look back at Pagely’s early years from 2006 to 2012. I tried not to get too technical or bore you with all the business details of our story. I hope you found some value in learning about our early system configuration and system design choices.
We are immensely proud of what we achieved, developing the first managed hosting service for WordPress. Today, we’re built entirely on Amazon Web Services which helps to power our blazing fast hosting solutions.
In true Pagely fashion, we have no plans to slow down.
I remember meeting you at SXSW. We talked about an interview about how you got to $20k in sales. Write. I’ve come a long way since then.